The Single-Record Merge Statement
I was looking for a very simple, pared-down example of a MERGE statement to use in teaching/training. Couldn't find one, so I made this one up.
In the process, I found that getting the @@IDENTITY value out of an inserted record in a MERGE statement is not supported. You have to set up a table variable to capture the IDENTITY-created value, then move it to a scalar variable.
This makes MERGE fairly clunky, in terms of code clarity, for this use case. However, there are certainly cases where the reduced seeks might make this worthwhile.
For this example, we'll use the Northwinds reference database Products table:
In the process, I found that getting the @@IDENTITY value out of an inserted record in a MERGE statement is not supported. You have to set up a table variable to capture the IDENTITY-created value, then move it to a scalar variable.
This makes MERGE fairly clunky, in terms of code clarity, for this use case. However, there are certainly cases where the reduced seeks might make this worthwhile.
For this example, we'll use the Northwinds reference database Products table:

So here's the desired task, written as a stored procedure without using the MERGE statement:
CREATE PROC changeProductPrice
@productID int = NULL,
@newPrice money,
@newProductName nvarchar(40),
@newProductID int = NULL OUTPUT
AS
IF EXISTS(SELECT * FROM Products WHERE productID = @productID)
BEGIN
UPDATE Products
SET unitprice = @newPrice
WHERE productID = @productID
END
ELSE
BEGIN
INSERT INTO Products
(unitprice, ProductName)
VALUES (@newPrice, @newProductName)
SET @newProductID = @@IDENTITY
END
GO
The situation is:
- there is a Product that may or may not exist as a record in the Products table
- if the Product already exists, we'd like to update the unitPrice
- if the Product record doesn't exist, we'd like to add the record
- we also want to return the productID of the product if it is a new record
This is a fairly classic issue - UPDATE if it's already there, INSERT if it isn't.
Using the Stored Procedure requires 2 seeks on the table:
- see if the record exists
- locate the record to either UPDATE or find the location to INSERT (this might be an append if ProductID is an IDENTITY field)
See the resulting query plan:

So here's how to do it as a MERGE statement:
CREATE PROC changeProductPriceMerge
@productID int = NULL,
@newPrice money,
@newProductName nvarchar(40),
@newProductID int =NULL OUTPUT
AS
DECLARE @newProductIDTable table(productID int);
MERGE Products
USING (SELECT @productID,
@newPrice,
@newProductName)
AS source (
productID,
newPrice,
newProductName)
ON (Products.productID = source.productID)
WHEN MATCHED THEN
UPDATE
SET unitprice = source.newPrice
WHEN NOT MATCHED THEN
INSERT ( unitPrice,
productName)
VALUES ( source.newPrice,
source.newProductName)
OUTPUT inserted.productID INTO @newProductIDTable;
SELECT TOP 1 @newProductID = productID FROM @newProductIDTable;
GO
But this is still a very pared-down example of MERGE.
Let's go through the main parts of the MERGE statement:
- MERGE - this is where we state which table will possibly be modified. In this case it is the Products table. This is sometimes renamed as [target] to be clear which table will possibly change.
- USING - this is where we define the data that will be used to:
- determine what will happen to records in the [target] (INSERT, UPDATE, DELETE, nothing)
- used as values to make something happen in the [target]
- ON - this must be a logical expression (evaluates to true or false), and is usually in the form of a JOIN-like expression that relates [target] and [source] records
- WHEN MATCHED - defines the operation to occur when the expression in the ON clause evaluates to true
- WHEN NOT MATCHED - defines the operation to occur when the expression in the ON clause evaluates to false
- OUTPUT - used to get the data that was affected by the MERGE statement. In this case, we are using it to get the database-generated IDENTITY value
The clunky portion to all this is that the OUTPUT clause can only accept a Table (or Table variable) in the INTO portion. As a result, it's necessary to create a Table variable, @newProductTable, to hold the new IDENTITY scalar value.
However, this is more of a declarative way to state this operation, and results in only a single seek on the Products table.
Here's the query plan for the MERGE version of the stored procedure:
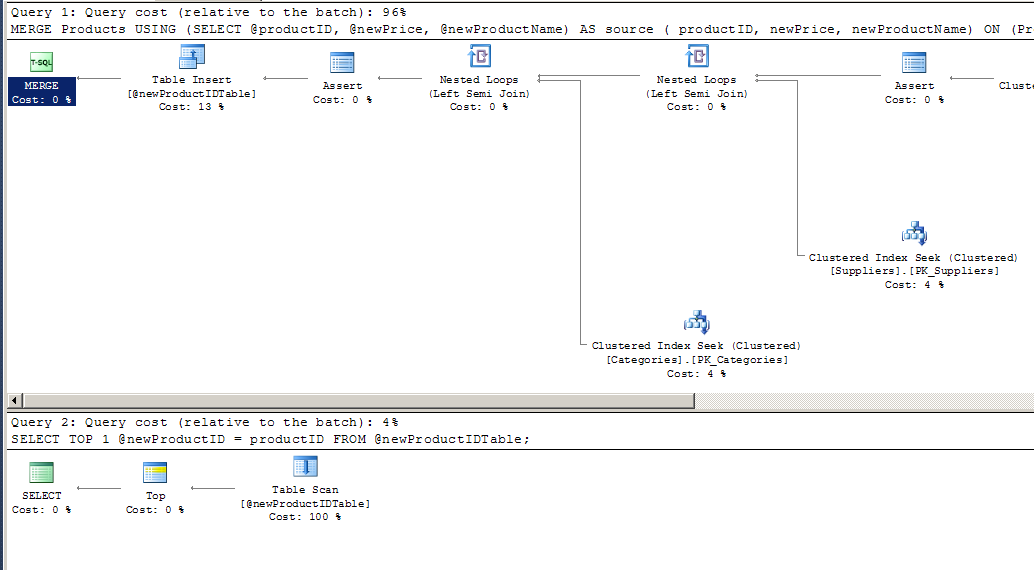
There are still two separate operations, due to the clunky handling of the new IDENTITY value in a table variable.
If the Products table were very large, and ProductID were not set as an IDENTITY field, the MERGE version might be faster. However, the MERGE version requires the instantiation of a table variable.
If we wrote this without providing the productID back as an OUTPUT, the MERGE version would certainly use only one operation.
All of this is not to say that MERGE is not helpful, but I think in this single-record situation, I'd choose the non-MERGE version for clarity.
If we wrote this without providing the productID back as an OUTPUT, the MERGE version would certainly use only one operation.
All of this is not to say that MERGE is not helpful, but I think in this single-record situation, I'd choose the non-MERGE version for clarity.
No comments:
Post a Comment